This module builds on the material from our Practicum AI Beginner Series and assumes a foundation in Python and deep learning basics. We will briefly revisit foundational deep learning concepts, focusing on how they relate to transfer learning. Additionally, we will expand on certain topics, such as learning rates and layer freezing strategies, and discuss how hyperparameters play a critical role in transfer learning:
Layer Freezing: During fine-tuning or some other model training techniques, specifying which layers to “freeze” depends on domain/task similarity. “Freezing” layers is a coding technique of specifying pre-trained layers of a model to not update their parameter weights during training. Freezing the earlier layers and fine-tuning the later layers is a common strategy when the source and target domains are similar. In dissimilar domains, unfreezing more layers allows the model to adapt to new features. After training a model with some frozen layers and some trainable layers, it is common to unfreeze the whole model, lower the learning rate, and finetune the whole model.
Conceptually, it’s important to keep in mind that with most network architectures, early layers tend to be more general and the later layers more specific.
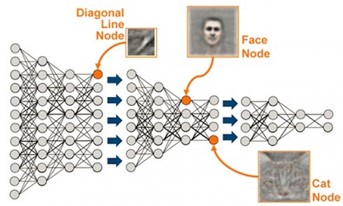
Figure 1. Representation of a deep neural network showing earlier layers capturing abstract features while later layers capture more specific features. Source - https://sdat.ir/en/sdat-blog/item/1-deep-learning, Accessed 29JAN25.
As seen in Figure 1’s representation above, computer vision models tend to capture features like horizontal or vertical lines in the earliest layers, while later layers tend to capture more complex combinations of features. The same is true for language models, with earlier layers primarily focusing on encoding low-level features of the input text, like individual words and their basic grammatical structure. They are essentially capturing the “building blocks” of the language, like how early layers in a vision network might detect edges in an image. Later layers in a deep network combine information from the earlier layers to learn more complex semantic relationships, context, and sentiment within a text.
This tendency motivates the idea of freezing some layers and leaving other layers unfrozen. For very similar tasks and/or domains, you may only want to unfreeze one to a few layers of a model before fine-tuning. For more divergent tasks and/or domains, you might want to unfreeze most or all the layers.
Learning Rate: Choosing an appropriate learning rate is crucial for transfer learning. Pre-trained layers typically require lower learning rates (e.g., 1e-5 to 1e-4) to avoid overwriting their learned features. Newly added layers, however, often benefit from a higher learning rate (e.g., 1e-3).
Batch Size: Remember that the best batch size is a complex tradeoff among several considerations, including GPU compute and memory capacity, model update frequency, and sample variability. Smaller batch sizes may be required when working with large pre-trained models due to memory constraints. However, the larger variability in small samples can introduce noisier gradient updates, so careful monitoring of validation performance is needed.
Regularization: Techniques like dropout are essential when fine-tuning pre-trained models to prevent overfitting, especially when the target dataset is small.
Optimizer Choice: Optimizers like Adam or SGD with momentum are commonly used. For fine-tuning, employing optimizers that allow for differential learning rates across layers can be advantageous.
Epochs: Transfer learning often requires fewer epochs compared to training from scratch. Early stopping can be used to avoid overfitting while ensuring efficient training.
By understanding and tuning these hyperparameters, you can effectively harness the power of transfer learning for diverse applications.
Transfer Learning Terms
Here is a rundown of some common terms and their meanings in the context of this course:
Task
- A specific problem the model is trained to solve, such as image classification, sentiment analysis, or object detection.
- Example: Classifying animals in photos.
Domain
- The type of data the model operates on, including its features and distribution.
- Example: A dataset of animal images or a collection of medical X-rays.
Source
- Refers to the pre-trained model, its task, or its domain from which knowledge is transferred.
- Example: A model trained on ImageNet. The source task (image classification) and domain (cropped images of 1,000 categories of objects).
Target
- Refers to the new model, task, or domain where transfer learning is applied.
- Example: Fine-tuning a model trained on ImageNet to classify dog breeds (same target task, slightly different domain).
Return to Module 1 or Continue to Key Techniques in Transfer Learning
