![]()
In exercise 1, we explored common issues with how data are organized in spreadsheets. We also provided a handout and the Broman and Woo 2018 paper with some best practices in organizing data in spreadsheets.
Then, in exercise 2, we explored the challenges with finding data associated with published literature and introduced the FAIR principles.
Now we turn to the process of making data available in data repositories.
Data repositories

Accessible, well-maintained, and efficiently operated data resources are critical enablers of modern biomedical research. (NIH ODSS)
Beyond biomedical research, any data-based research requires accessible, well-maintained and efficiently operated data resources.

While Clive Humby was thinking of marketing and business, data are more and more central to modern research.
With much of academic research funded through tax dollars, government funding agencies have started requiring making data produced through their funding available, with appropriate authentication and authorization, to further research. To facilitate making data available, an ecosystem of data repositories has grown, allowing researchers to deposit, cite, find and reuse data.
Domain-Specific vs. Generalist Repositories
Many domains have established one or more data repositories to house data associated with studies in that particular domain. These domain-specific repositories can be tailored for the best practices for particular types of data, for example GenBank is “the NIH genetic sequence database, an annotated collection of all publicly available DNA sequences.” Other domain specific repositories are available in many disciplines and are typically a best first choice for depositing data.
Often researchers have data that do not fit well in a single, or any, domain specific data repositories. Or raw data may be in a domain specific repository, but analyzed or combined datasets may be of value and can be deposited in generalist repositories. These repositories contain a wide array of data and while they maintain flexibility in the data types and formats deposited, this flexibility can reduce findability and reusability. One example of a generalist repository is Zenodo.
Developed by CERN (the home of the Large Hadron Collider) and funded by the European Union, Zenodo is one of the leading generalist data repositories, with datasets ranging from physics to ecology and biomedicine.
Student Instructions
In this exercise we will work with data in both a domain-specific and a generalist repository.
Domain-specific repository
- Visit this listing of Domain-specific repositories maintained by NIH.
- Browse the list of repisitories and identify some that may be of interest to you.
- For this exercise, we will use the National Sleep Research Resource
- Our fitness tracker developer has realized that there is significant interest in tracking sleep patterns and wants to see what data are available to support linking sleep patterns to health.
- Starting at https://sleepdata.org/, locate the main page for the Sleep Heart Health Study.
- How did you get there?
- Here’s the page we were trying to find.
- Did you find the same page?
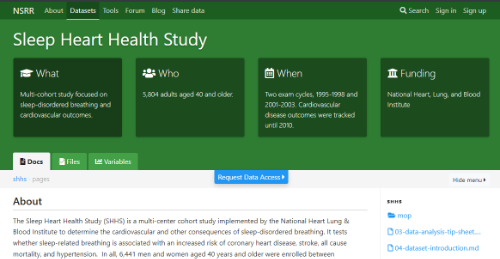
- Did you find the same page?
- Look through the metadata on the page. Are you able to answer these questions?
- How were the data collected?
- When were the data collected?
- How would you cite the data if you used them?
- How would you get access to the data?
- Any metadata you think is missing?
- Overall, if you were a sleep researcher, how useful do you think the National Sleep Research Resource would be?
Generalist repository
- Visit the listing of Generalist repositories maintained by NIH.
- How many of these do you recognize?
- For this exercise, we will use Zenodo
- Enter the search term “sleep heart” and search.

- Scroll down to the “Type” selection box on the left and select “Dataset”
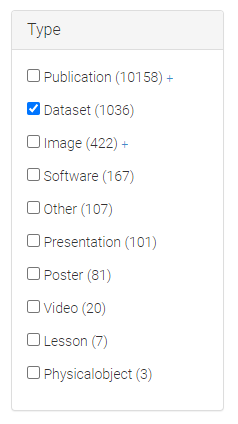
- Select a dataset (does not necessarily need to be related to our fitness tracker) and answer the same questions
- Look through the metadata on the page. Are you able to answer these questions?
- How were the data collected?
- When were the data collected?
- How would you cite the data if you used them?
- How would you get access to the data?
- Any metadata you think is missing?
- Overall, if you were a sleep researcher, how useful do you think Zenodo would be?
- Using Zenodo, think of some other search terms you may be interested in. Are you able to find information related to that in Zenodo?
