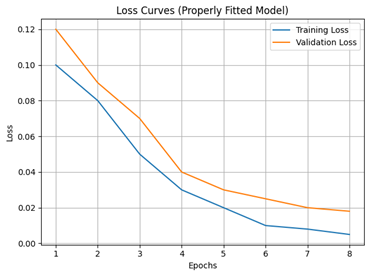
Supervised learning models aim to learn the relationship between input data and desired outputs. Striking the right balance between complexity and accuracy is crucial. Here, we explore two common issues in model training: overfitting and underfitting. As a guideline, if a model’s accuracy improves on training and validation, the model is generalizing well (though it could still have other issues, such as low accuracy…). Here is an example loss graph showing a model that is probably fitting properly:
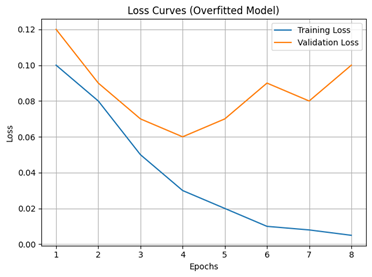
Overfitting occurs when a model becomes too focused on the specific training examples it has been shown. It essentially memorizes the training data rather than capturing the underlying patterns that generalize to unseen data. Symptoms include high accuracy on the training set but poor performance on new data. Here is an example loss graph showing a model that is probably overfitting:
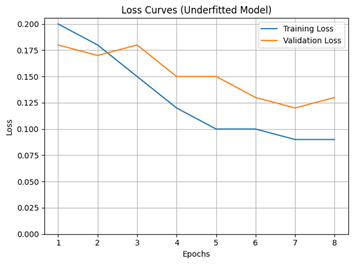
Underfitting, on the other hand, happens when a model is too simple and lacks the capacity to learn the complexities within the training data itself. This leads to low accuracy on both the training and validation sets. Here is an example loss graph showing a model that is probably underfitting:
Tips for Tackling Overfitting and Underfitting
To combat overfitting, we can employ techniques like
- Data augmentation, where we artificially create new training examples. This is usually done by making common-sense changes to existing data (like taking a sample picture and mirroring it, thus giving us two useful samples from one).
- Regularization, where we penalize overly complex models. Some popular examples of regularization are Dropout (having the model randomly “turn off” some number of neurons during each epoch to prevent overreliance on them) and Early Stopping (having the model stop training early if it detects overfitting).
For underfitting, we can employ strategies like
- Using more complex models (with more layers, neurons, more sophisticated activation functions, etc.).
- Increasing the amount of training data.
- Employing feature engineering to reduce the model’s complexity. We want to remove redundant or highly correlated features!
