What exactly are neural networks and deep learning? The core of deep learning is the neural network. A neural network is a particular learning algorithm inspired by the billions of interconnected neurons in the human brain. It consists of interconnected nodes (analogous to neurons) that process information in layers. Each connection has a weight, which gets adjusted during training, allowing the network to “learn” from data and make predictions.
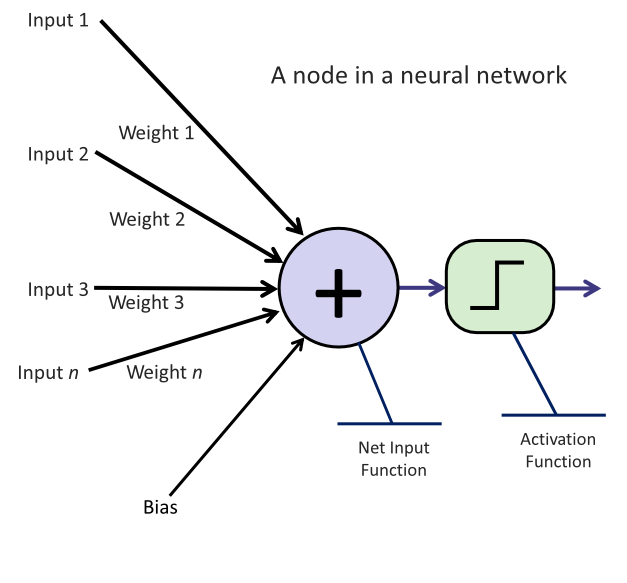
Module 2 will provide more details, but we will introduce some vocabulary here. Each input connection is assigned a weight for each node (or neuron). The input value is multiplied by the weight, and all these products are added together. Each node also has a bias term that is added to the sum. That sum is the raw output of the neuron. Neurons can have an activation function, which modifies the output before passing it on to the next node in the network. Activation functions enable non-linear functions to be learned, and which function to use is one of the hyperparameters or model settings you can set in training.
In a deep learning AI model, neurons are grouped in layers, as in a multi-layered cake. If you have many layers, the cake is “deep” when viewed from above. And that’s why we say “deep learning.”

As an analogy, imagine a factory assembly line that takes raw input materials and has several stations where workers perform some function to produce a product. There is an example product that the workers aim to replicate. Each station (a node or neuron) in our factory has a specific task. Raw materials (input data) are entered at the beginning, and each station makes slight modifications. By the time the materials reach the end of the assembly line, they’ve been transformed into a finished product (output or prediction). The product of the assembly line is then compared to the example product. The factory workers then adjust their tools or methods by comparing outputs to the ground truth to produce better products. Similarly, a neural network adjusts its weights based on the difference between its predictions and the actual outcomes, improving its accuracy over time.
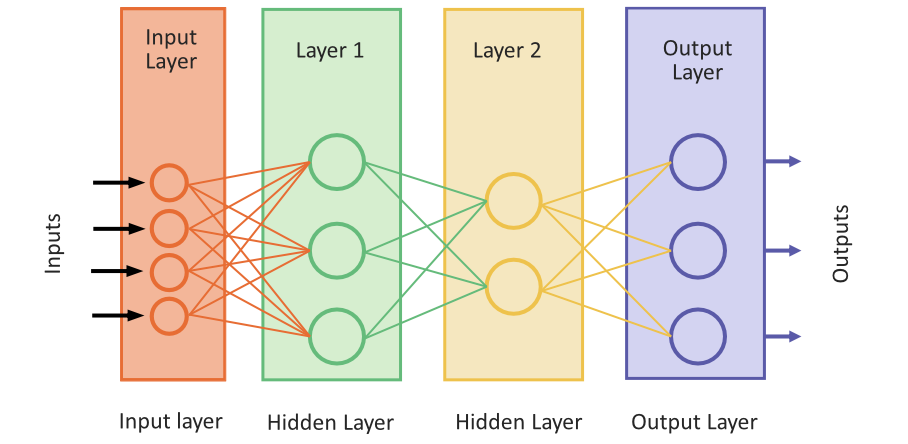
A neural network is a series of interconnected nodes that aim to transform input data into meaningful output. In practice, there are typically many (thousands) of neurons in layers, and each layer takes input from the previous layer in the network and feeds its output to the next layer.
- Nodes or Neurons: These are the fundamental units of a neural network. Each node receives information, processes it, and then sends it onward. We’ll go deeper into how exactly nodes work in the next module.
- Layers: A typical neural network is organized into three main types of layers:
- Input Layer: The first layer where data enters the system.
- Hidden Layers: These are layers that sit between the input and output layers. The data undergoes multiple transformations as it passes through these layers. There can be one or many hidden layers in a network. The term hidden layer refers to the fact that we don’t see the details of how they operate—while we see the input going in and the output coming out, we don’t directly see the operations in the middle.
- *Output Layer: The final layer produces the result or prediction.
- Weights: These are values associated with the connections between nodes. They determine the importance or influence of one node’s output on another. During training, these weights are adjusted to minimize the difference between the network’s predictions and the actual outcomes.
- Activation Functions: Each node in the network has an associated activation function. It decides how the information the node has processed should be transformed before being passed forward. Think of it as a filter that amplifies, diminishes, transforms, or maintains the signal it receives.
Training a neural network involves feeding it training data with known outcomes, having it make predictions, and then adjusting the weights based on how close or far its predictions are from the actual outcomes. This process is repeated many times, and the network becomes more adept with each iteration.
In essence, neural networks are like finely tuned machines that, over time, learn the best way to process information to achieve a desired outcome.
