Here are some examples of the general tasks in computer vision:
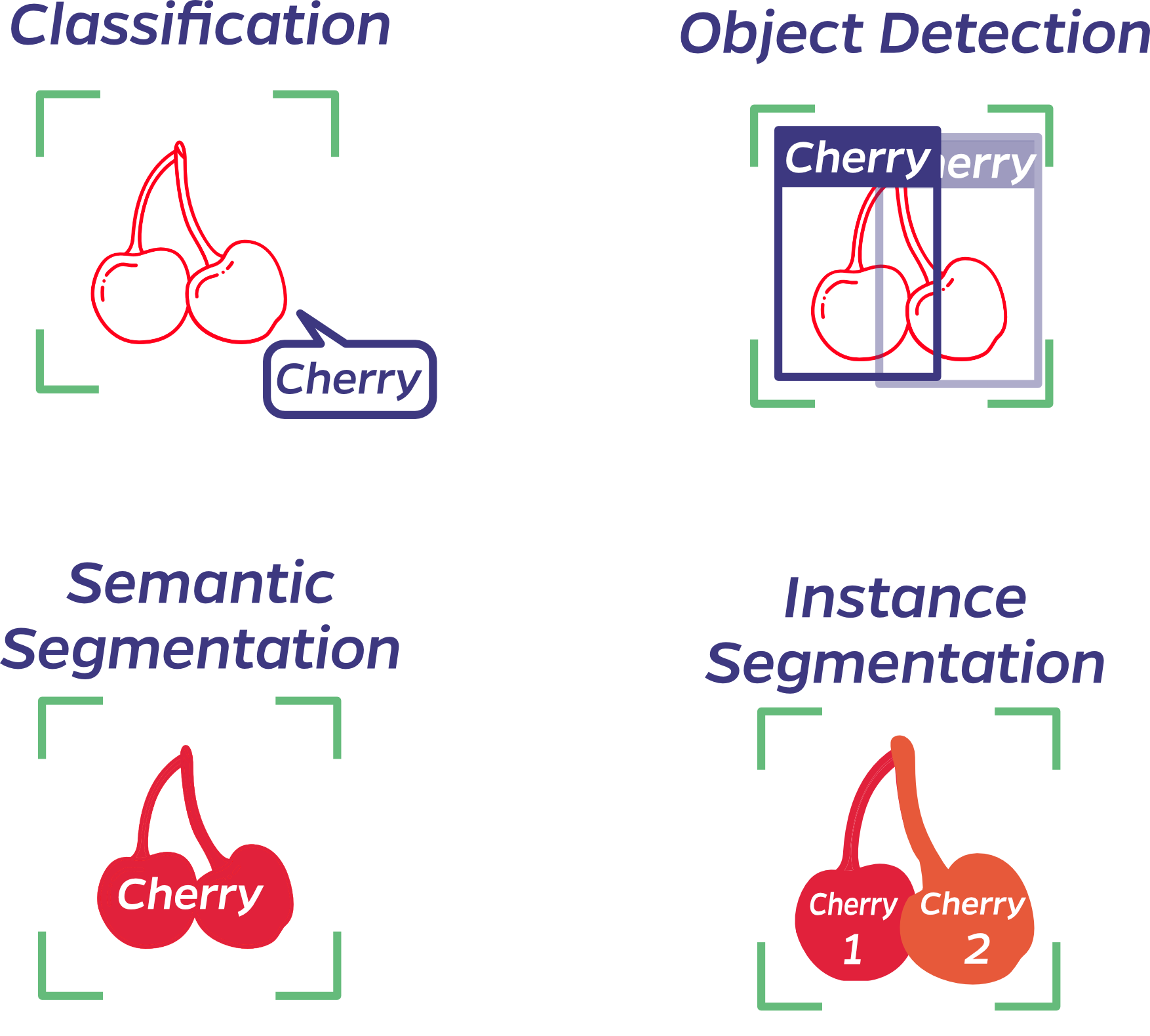
Image Classification: This is the process of categorizing images into predefined classes. Technically, it involves using algorithms like CNNs to process pixel data and extract features, which are then used to classify the image. It’s a single-label problem in which each image is assigned to one label from a set of categories (such as ImageNet’s 1,000 categories of various images).
Object Detection: This goes beyond classification to identify specific instances of objects within an image and their boundaries, typically represented by bounding boxes. Techniques like R-CNN (Region-based CNN) or YOLO (You Only Look Once) are employed, which involve both classifying the objects present and localizing them within the image.
Semantic Segmentation: All pixels that belong to the same class, or “type of thing,” are assigned the same label, but individual objects aren’t distinguished. This means if two cherries are in an image, all pixels within them will have the same label without differentiating among them.
Instance Segmentation: Going a step further, instance segmentation not only labels pixels belonging to the same class with the same label but also distinguishes among different instances of the same class. If there are two cherries, each charry would be uniquely identified. Another way to think about instance segmentation is the combination of semantic segmentation and object detection: each pixel gets a class label, as in semantic segmentation, and each object instance gets its own bounding box, as in object detection.
Specialized Computer Vision Tasks
Instance-Level Recognition: Building on image classification, instance-level recognition seeks to identify specific instances of a class. Common applications are in landmark labeling and facial recognition. For example, in the image below, the task is to label the center image as “Arc de Triomphe de l’Étoile, Paris, France” instead of simply “arch.”

Google’s DEep Local and Global Features (DELG) model uses two CNNs: one focused on local features in an image and the other focused on global features.
Facial recognition identifies or verifies a person’s identity using their face. It encompasses several processes, including face detection (locating a face within an image), feature extraction (using landmarks or key points on the face), and matching against a database of known faces.
Depth Estimation: This technique predicts the distance from the viewpoint to the objects in a scene for each pixel. It can be achieved through methods like stereo vision, where the disparity between images from two cameras is used, or by using deep learning models trained on labeled depth data to predict depth from a single image.
Keypoint Detection: Keypoint detection models are trained to detect specific keypoints, a joint on a person or robot, for example. These models can identify the position and orientation of one or several keypoints, allowing tasks like pose estimation using the spatial locations of key body joints (like elbows, wrists, ankles, etc.). This can be 2D, where the model predicts points on the image plane, or 3D, which involves predicting the position of points in three-dimensional space.
Return to Module 1 or Continue to Computer Vision Neural Networks
